Em Free Icon Packs é possível baixar diversos pacotes temáticos de ícones para utilização gratuita nos seus programas/páginas (pessoais ou comerciais). Pessoalmente eu prefiro ter os ícones no meu computador. Como aqui não é Netflix ou outro serviço do gênero, vou colocar todo o conteúdo em um texto sem parte 1, parte 2 e parte 3. Nem terá a segunda temporada. Vai ser um filme e não uma série. 😉
Procedimento manual
Para baixar os ícones manualmente eu teria que:
-
Percorrer 15 páginas, baixando 15 arquivos compactados de cada página (225 arquivos)
-
Descompactar os 225 arquivos compactados
Bem, para a primeira etapa eu teria que clicar no pacote para abrir a página para download, ir até aparte inferior, clicar no botão para download, clicar em salvar, voltar para a página anterior. Supondo que levasse um segundo para cada etapa, seriam 5s por cada pacote. Multiplicando seriam 1125s com cliques e rolagens. Arredondando, uns 19 minutos para a tarefa (se nada ocorrer errado).
A segunda parte demandaria mais dois cliques por arquivo (botão da direita mais descompactar par a a pasta). Arredondando, mais uns 8 minutos.
Poderia baixar um por dia que nem sentiria durante os 225 dias.
Definitivamente, está fora de cogitação efetuar a tarefa manualmente.
Em vez de perder tempo em uma tarefa repetitiva, que deveria ser exclusividade do computador, vou escrever uma receita de bolo para o computador trabalhar. Assim me divirto um pouco e posso aprender alguma coisa nova.
Automatizando o processo
Poderia ter feito todas as etapas utilizando apenas uma linguagem já que todas fazem de tudo. Mas optei por uma abordagem diferente. Utilizar a linguagem que eu acharia mais adequada para cada tarefa.
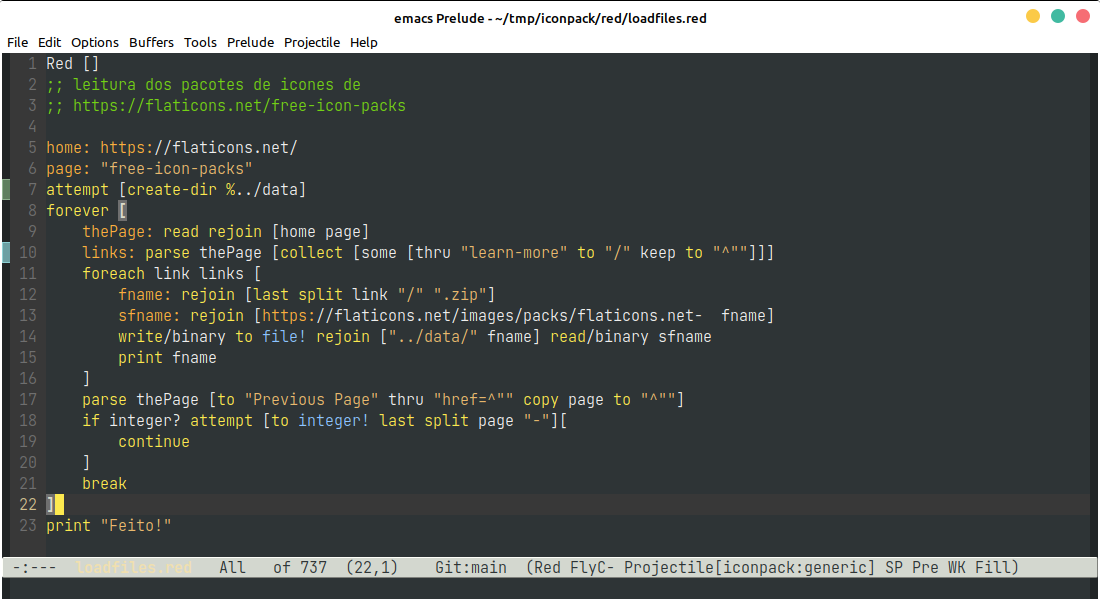
Primeira etapa – Baixar os arquivos – Red
O processo é fácil. Temos que ler a página, extrair os links, baixar os arquivos e repetir o processo para a próxima página até a última. O programa poderia ser escrito com uma das mil linguagens que podem executar a tarefa, mas escolhi Red. Acho o parser de Red muito mais fácil de utilizar do que ER sem contar a sua integração com a linguagem. A leitura de um arquivo seja ele local ou na internet é o mesmo. Roda no Linux/Windows/Mac, pode ser compilada ou interpretada. O único defeito, no momento, é que só existe a versão 32 bits (estão trabalhando na versão 64bits).
Ler a página
Para ler a página e colocar o conteúdo na variável thePage (variável não é o termo correto em Red mas fica assim para facilitar) basta escrever:
thePage: read https://flaticons.net/free-icon-packs
Simples, não? E olha que REBOL, a linguagem em que Red se baseia é de 1997. Uma facilidade que existia há 26 anos (pode ser mais velha do que muitos que acessam o TabNews). A atribuição é feita pelos dois pontos (como se fosse em um CSS)
Coletar os links para cada pacote da página
Cada página necessita de um estudo para saber onde as coisas estão entre aquele monte de tags para que possamos extrair as informações desejadas. Precisei da seguinte linha para coletar todos os links para os pacotes da página e colocar em um array (também não é o termo correto utilizado por Red):
links: parse thePage [collect [some [thru "learn-more" to "/" keep to "^""]]]
Analisando o bloco do parse:
-
some: irá executar o bloco entre colchetes uma ou mais vezes. -
thru "learn-more": irá procurar pela expressão learn-more e colocar o cursor logo após o último e. -
to "/": irá procurar a primeira barra após o cursor e posicioná-lo no local da barra. -
keep to "^"": irá coletar todo o conteúdo do cursor até antes da primeira aspa que encontrar e passar para ocollectpara montar o array com os links
O parse também já existia em REBOL há 26 anos. Legível e integrado com a linguagem e não aquele monte de símbolos das expressões regulares que ficariam mais bonitos em linguagens com APL, J, K e outras parecidas.
Ler os arquivos
Depois é só usar um loop foreach para cada link da array links, montar o endereço e e usar write/binary arquivo-local read/binary arquivo-remoto (veja novamente que não existe distinção se o arquivo é local ou remoto, read e write funcionam para os dois e mais um monte de coisas).
Próxima página
O processo é igual ao utilizado para catar os links da página.
parse thePage [thru "Previous Page" thru "href=^"" copy page to "^""]
- coloca o cursor após Previous Page, move o cursor após “href=^”" copia todo o conteúdo até encontrar a primeira aspas. Nem preciso dizer que copiou o link para a variável
page.
Agora é só voltar para ler a próxima página, se o link for válido, efetuando os mesmos procedimentos.
Final da primeira etapa
O programa final ficou com 23 linhas (incluindo duas linhas de comentário e uma em branco).
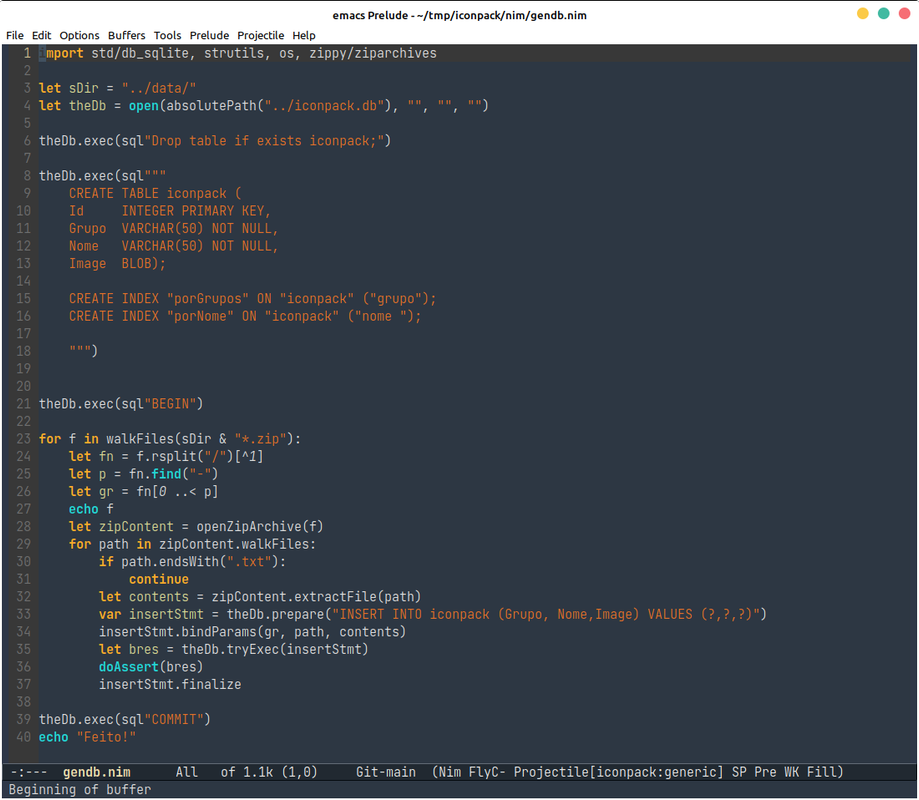
Segunda etapa – Extrair arquivos – Nim
Resolvi extrair todas as imagens dos arquivos compactados e colocar em uma base de dados (SQLite) para facilitar a futura pesquisa das imagens.
Novamente, poderia ter escolhido qualquer uma das trocentos mil e 4 linguagens disponíveis. Mas escolhi Nim. A sintaxe é bem semelhante com Python, pode gerar código para C/C++ e compilar ou JavaScipt.
O programa para criar o DB, extrair todas as imagens dos arquivos compactados e incluir no DB ficou com 40 linhas (7 são linhas em branco). Ficou assim:
Terceira etapa – Programa para visualizar as imagens – Lazarus
Aquele papo das trocentas linguagens e escolhi Lazarus (freePascal). Para criar um programa com uma interface gráfica, o maior concorrente seria o Delphi (mas aí você vai pagar beeeeeem mais caro).
Basta arrastar os componentes para a janela, informar algumas propriedades (nome do banco de dados e SQL para a seleção dos registros e algumas ligações e está pronto). Ok. Precisaria de alguns controles para selecionar os grupos ou um nome e montar a SQL para filtrar as linhas mostradas. O Basicão ficou assim:
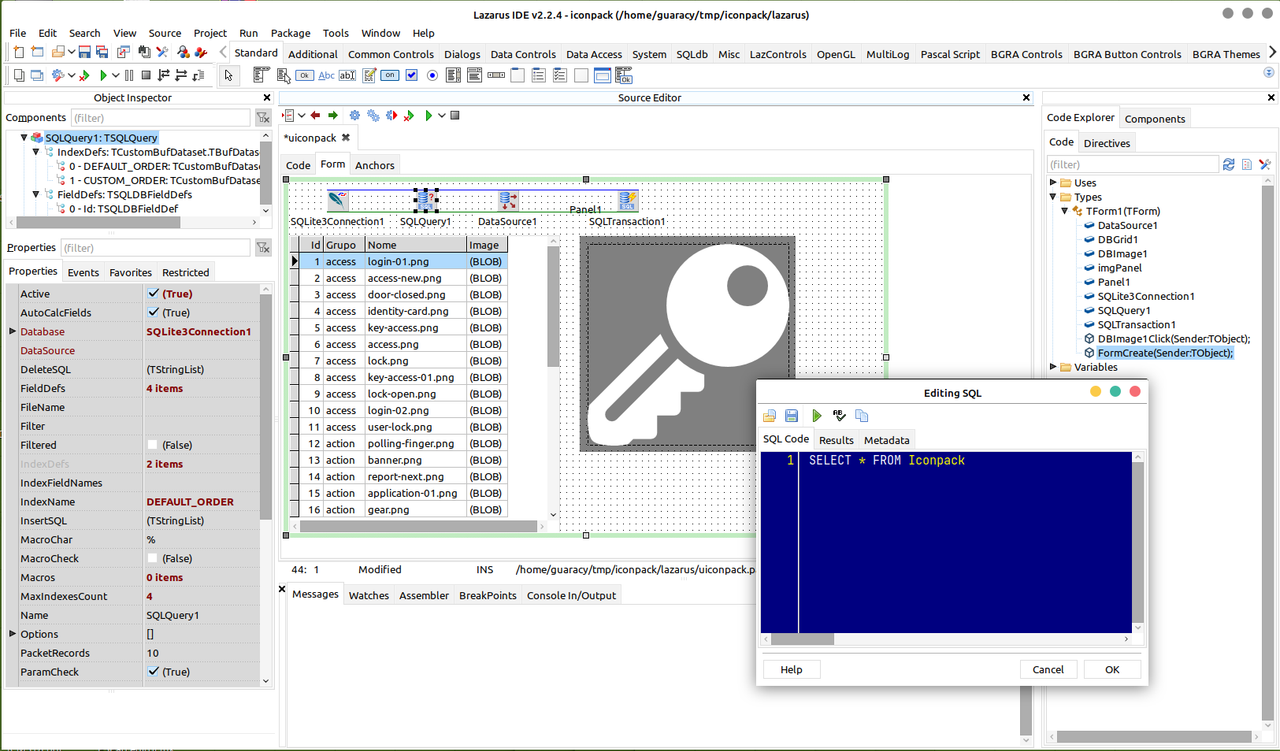
Para não dizer que não escrevi nenhum código, escrevi o seguinte no evento onClick da imagem:
DBImage1.CopyToClipboard;
ShowMessage('Copiada para a área de transferência.')
Quando o usuário clicar na imagem, ela é copiada para a área de transferência e mostra a mensagem. Depois pode ser colada em outro programa.
Fim
E era isso. Quando eu tiver um tempinho e vontade, vou incluir algumas opções de pesquisa, colorização do ícone e outras frescura.
Vejam que foram utilizadas três linguagens diferentes. Na minha humilde opinião, as que eu achava mais adequadas para cada tarefa. Nenhuma linguagem da moda.





